Compute Flexibility: Why AI Data Centers Are Becoming Grid-Aware by Necessity
Compute Flexibility: Why AI Data Centers Are Becoming Grid-Aware by Necessity
AI is scaling fast, GPUs are everywhere, and yet power is increasingly the constraint that matters most. This is where a new concept called data center flexibility comes into play. Traditionally, data centers were treated as fixed assets, with little ability to adjust operations in response to external factors such as grid conditions or resource availability, largely because power was not perceived as a limiting factor. As a result, operational guidelines emphasized redundancy and stability rather than adaptability.
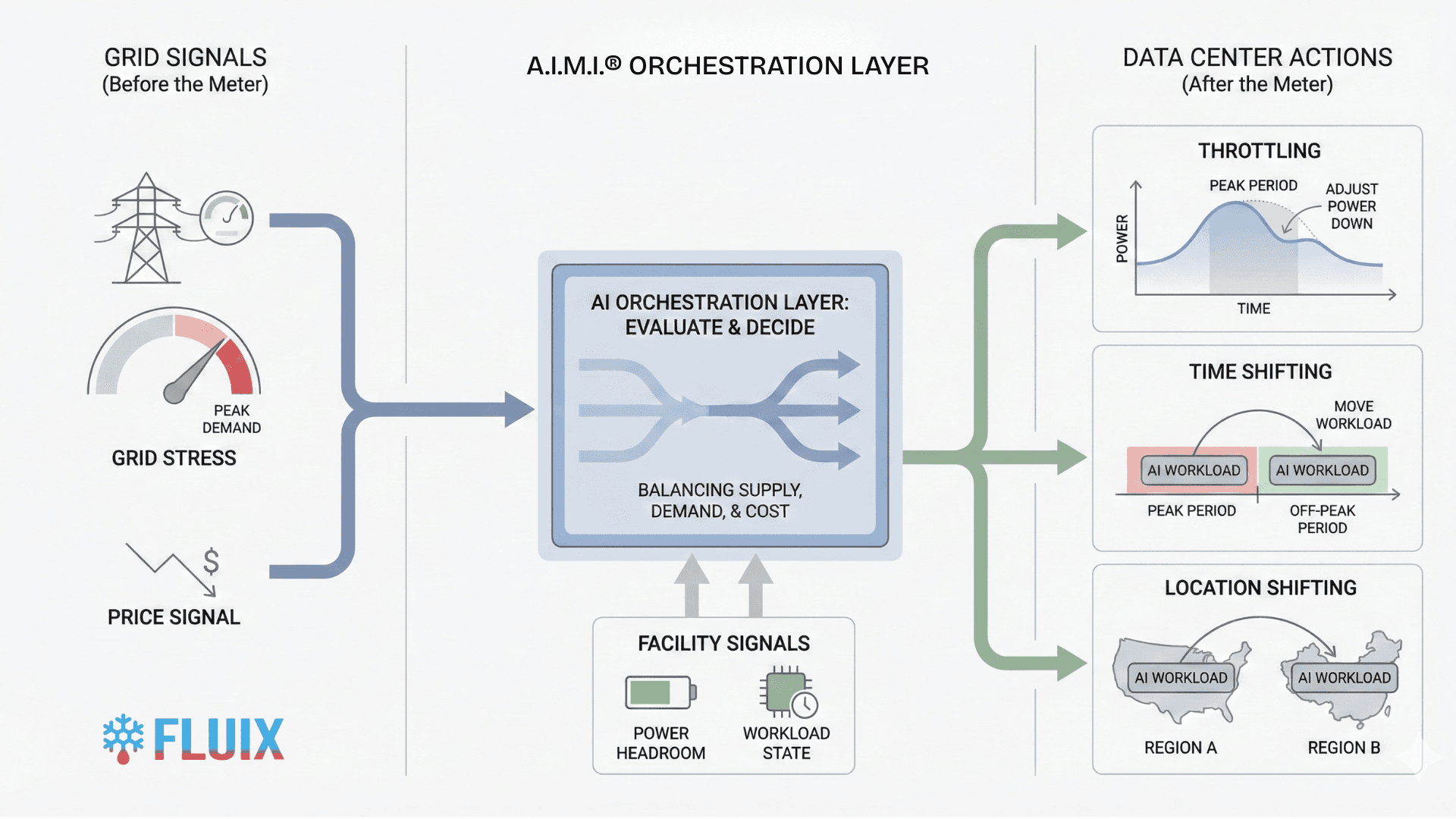
There are three main arenas for data center flexibility: power, cooling, and compute, each with its own methods, technologies, and challenges. Compute flexibility is our focus today, as it remains the least understood, particularly given how rapidly chips and networking equipment are evolving to support increasingly demanding workloads like AI training and inferencing. It is also the most complex, requiring more intelligent technology solutions and, in many cases, a new operational manual for how data centers are run. Sometimes described as GPU orchestration or grid-aware scheduling, the label matters less than the shift itself. AI workloads are beginning to behave less like fixed demand and more like something the grid can actively respond to.
The Mismatch Between AI Workloads and Power Availability
Data centers have always been built around peak load, with electrical systems, cooling infrastructure, and utility contracts sized for worst-case conditions, a model that begins to break down under modern AI training patterns.
Large training jobs often start simultaneously, driving rapid increases in power draw, which in turn raises cooling demand and operating costs, and in many regions, utilities respond by limiting additional power during peak windows to protect grid stability. The result is counterintuitive but increasingly common: facilities can be filled with GPUs and still be unable to run them all at once. The constraint is not hardware availability, but timing.
This dynamic has been documented repeatedly by grid operators and energy researchers. The International Energy Agency has warned that AI-driven data center growth is introducing “sharp increases in electricity demand over short time periods” (International Energy Agency, Electricity 2024 – Analysis and Forecast to 2026), a load profile that power systems are not designed to absorb efficiently without flexibility mechanisms in place.
Not All Compute Is Equal
The key insight behind compute flexibility is simple: not all compute needs to run immediately. Some workloads are inflexible. Real-time inference, user-facing services, and latency-sensitive systems must respond the moment they are called. Others are inherently flexible. Training jobs, batch analytics, ETL pipelines, and large offline experiments can often finish later without a meaningful impact.
A large portion of AI training falls into this second category. If a training job completes overnight instead of early evening, the outcome is unchanged. The model still converges. The work still ships. Compute flexibility takes advantage of that difference by shaping when and how flexible workloads run so they align with periods when power is cheaper, cooling is easier, or the grid is under less stress.
A.I.M.I. was built specifically to operationalize that distinction, turning flexibility from a theoretical concept into a controlled, system-level capability.
Compute Flexibility in Practice: Throttling, Time Shifting, and Location Shifting
Compute flexibility is not a single technique. In practice, it emerges from three closely related mechanisms: throttling, time shifting, and location shifting. Each has existed in some form for years. What has been missing is a system that can coordinate them in real time, with awareness of workloads, facilities, and grid conditions simultaneously.
That orchestration gap is where A.I.M.I. operates.
Compute Throttling: From Blunt Limits to Coordinated Control
One of the earliest approaches to compute flexibility was throttling, where GPU workloads operate below peak power when constraints require it. Instead of assuming full utilization at all times, throttling allows workloads to adapt their power draw while continuing to execute safely and predictably.
Large cloud operators explored this years ago. Google has described how power-aware scheduling and deferrable workloads can reduce peak demand, provided workloads can checkpoint and recover safely (Google, Data Center Efficiency and Demand Flexibility). Microsoft has shown that power capping can help facilities stay within electrical limits, but only when decisions are coordinated across workload scheduling and infrastructure controls rather than applied blindly at the hardware level (Datacenter Power Management).
What these efforts revealed is why throttling never became a default operating mode. Without tight coordination between workload state, scheduler behavior, and facility constraints, throttling often produced unpredictable performance degradation or operational instability. As a result, most implementations remained coarse, static, or reserved for emergency conditions. The limitation was not hardware capability. It was orchestration.
This is where AIMI changes the model. Instead of imposing static caps, AIMI continuously shapes GPU power draw based on live signals from the facility and the scheduler, reducing demand gradually during constrained periods and restoring full performance when conditions allow.
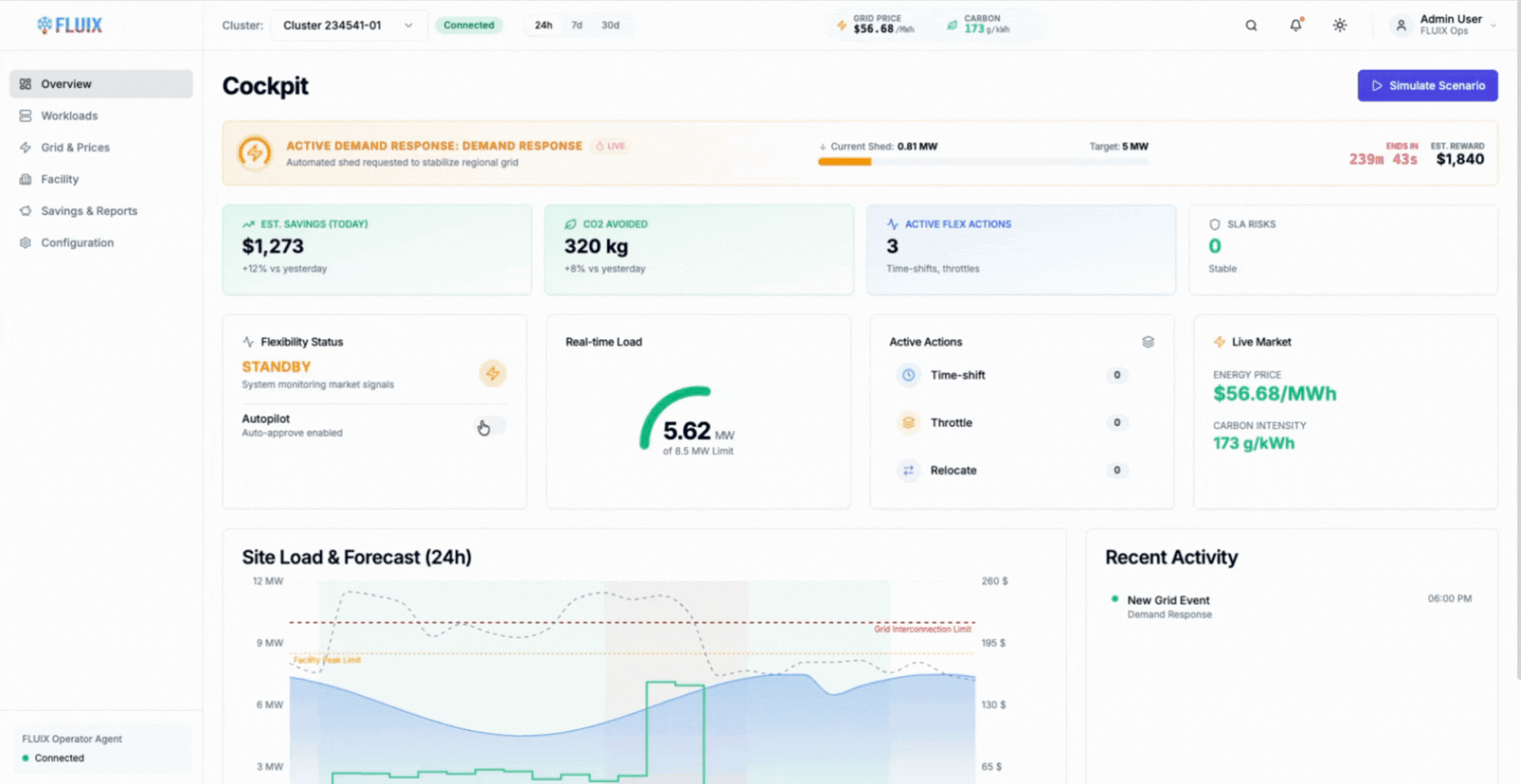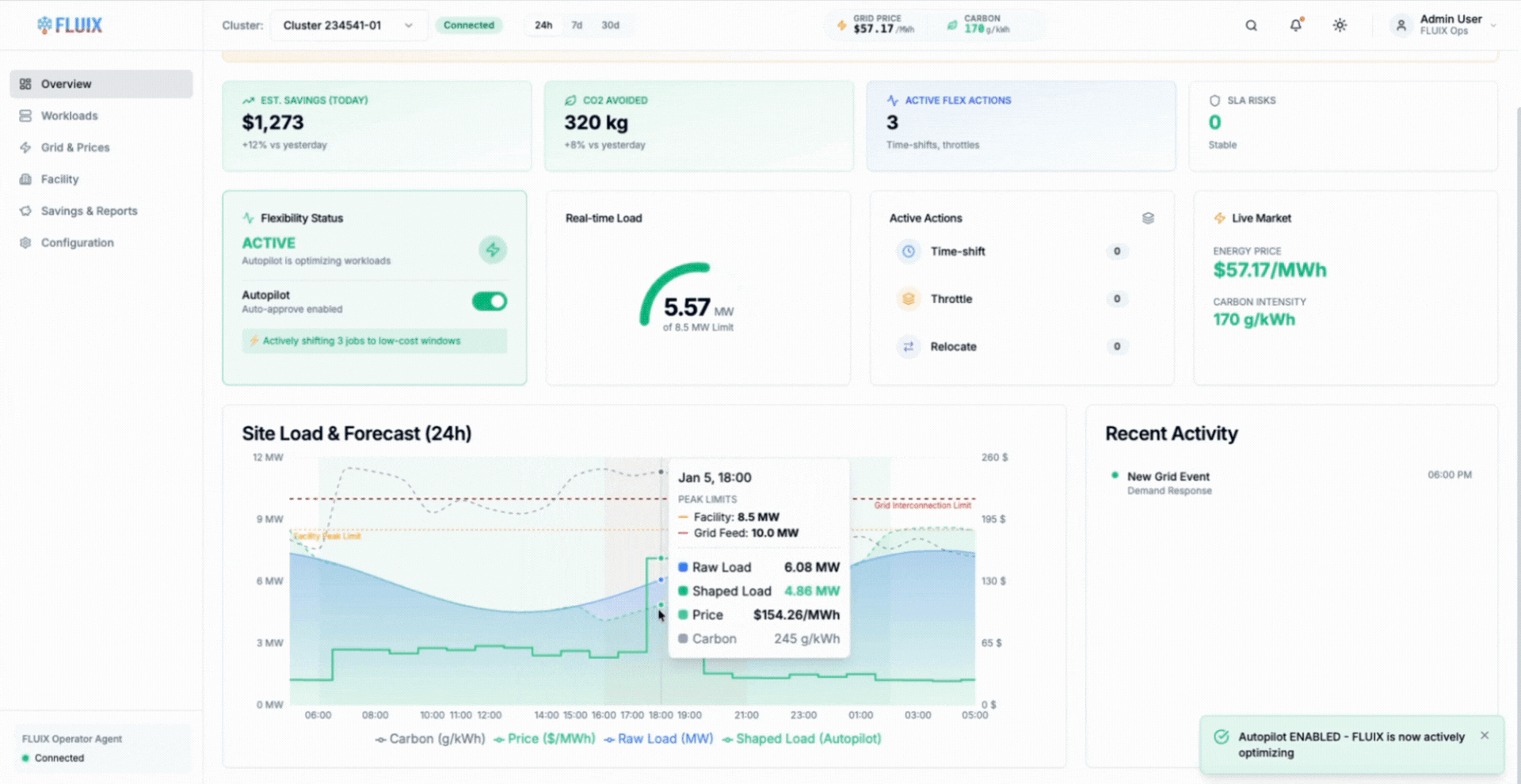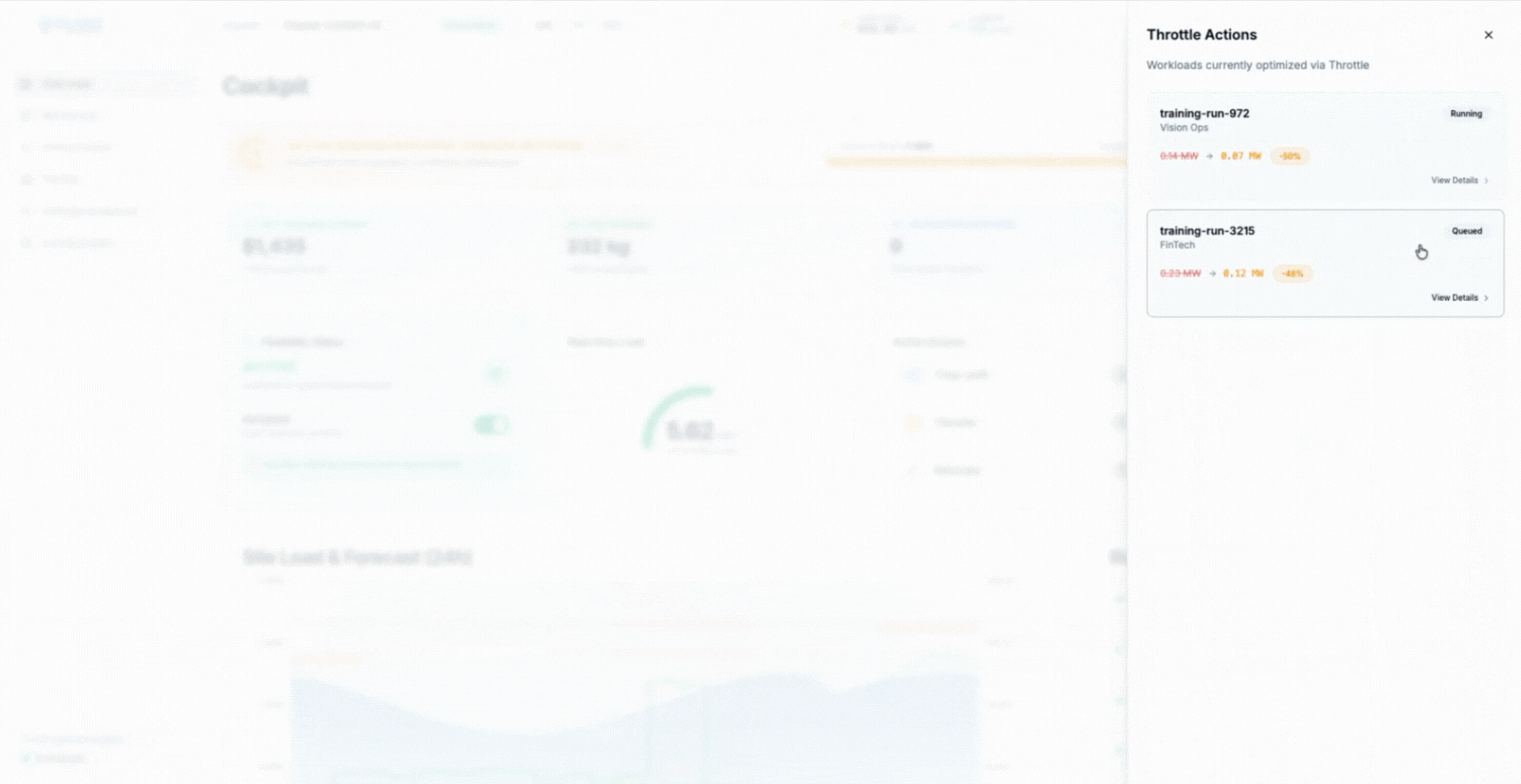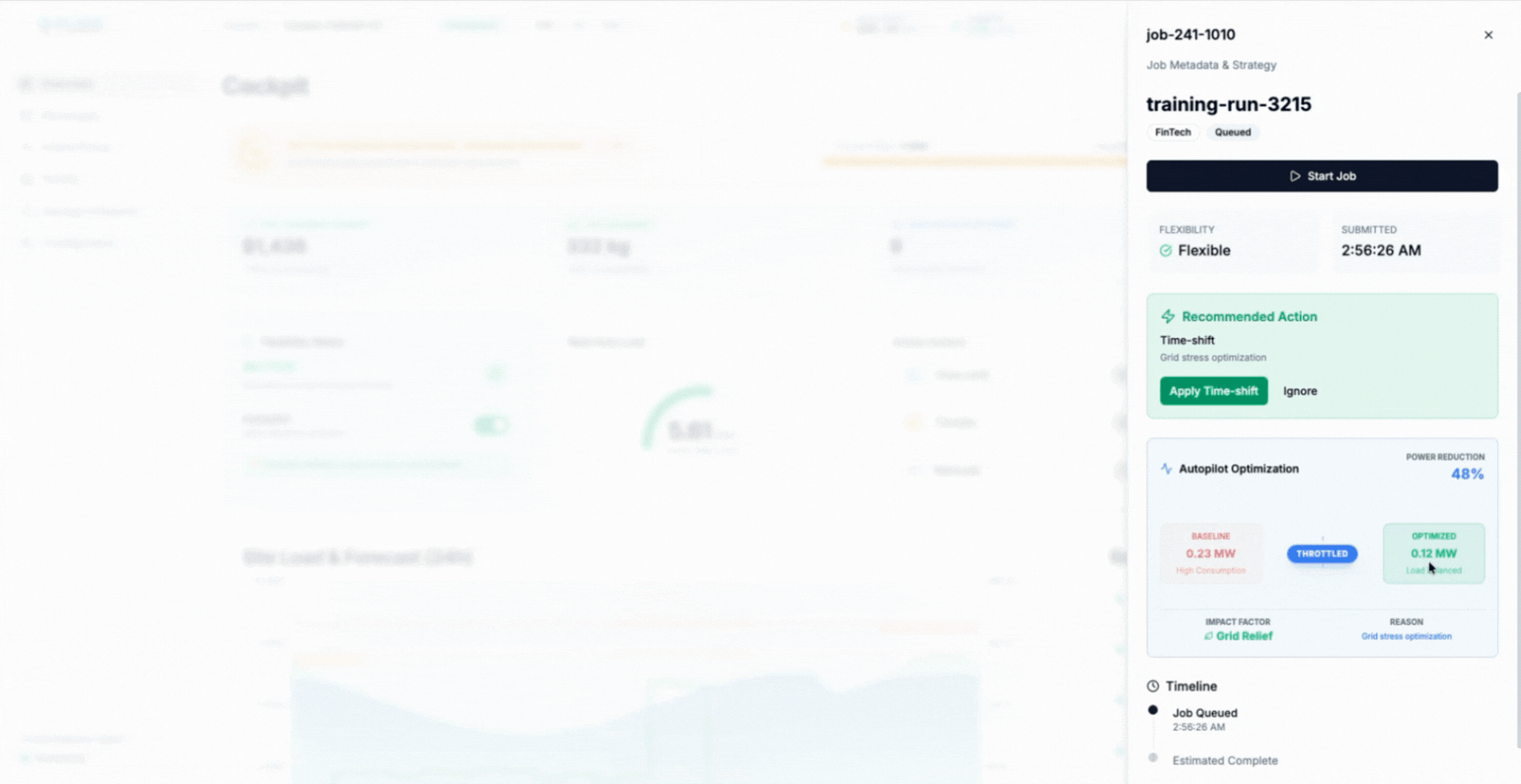
The animation shows AIMI dynamically adjusting GPU power across eligible training workloads, keeping the facility within power and thermal limits while allowing work to continue uninterrupted.
Time Shifting: Flexible Work, Smarter Timing
Time shifting addresses the same problem from a different angle by changing when work runs rather than how fast it runs. Non-urgent workloads can pause or slow during periods of grid stress or peak pricing, then resume later when conditions improve. The work is not cancelled or restarted. It is moved in time.
This idea has been used at scale for more than a decade in batch computing environments. Google has described how internal schedulers defer non-urgent jobs to manage energy cost and capacity constraints, noting that delay-tolerant workloads can be shifted without impacting user-facing services (Google, Data Center Efficiency and Demand Flexibility). Systems such as MapReduce and Borg formalized the separation between latency-sensitive services and deferrable batch compute, making time shifting viable in principle (Google, Borg: Large-scale cluster management).
Adoption was limited by execution. Early schedulers understood job priority but lacked visibility into real-time power headroom, cooling constraints, or grid events. Time shifting was therefore static and conservative, driven by fixed rules instead of live conditions, which increased the risk of missed deadlines and made operators hesitant to rely on it operationally (Google, Power-aware computing).
Modern AI workloads change that equation. Training jobs are increasingly checkpointable and tolerant of interruption, allowing work to pause safely and resume without loss (Google, Efficient checkpointing for large-scale machine learning). AIMI builds on this by time-shifting workloads automatically based on real-time facility and grid signals, without manual intervention or static schedules.
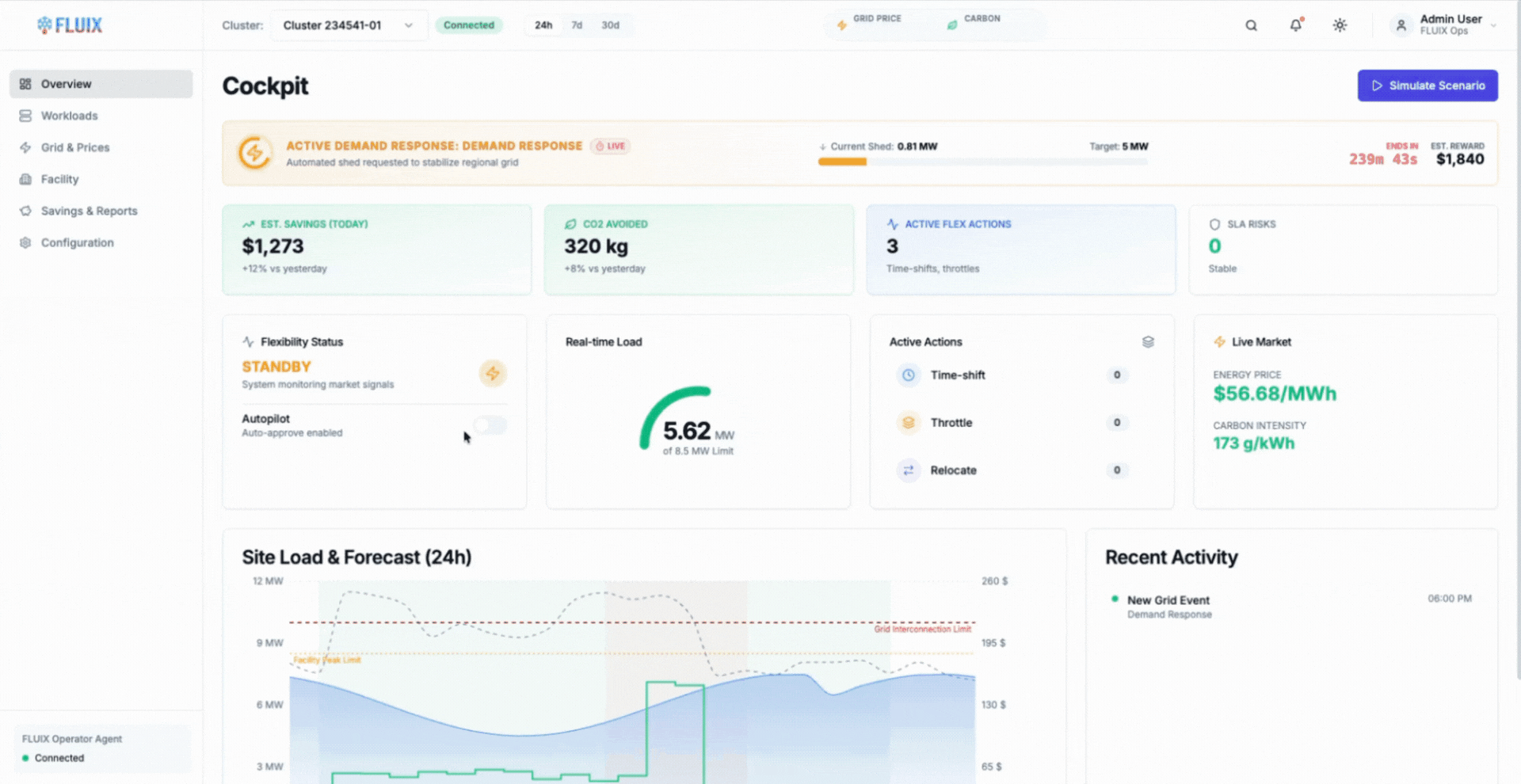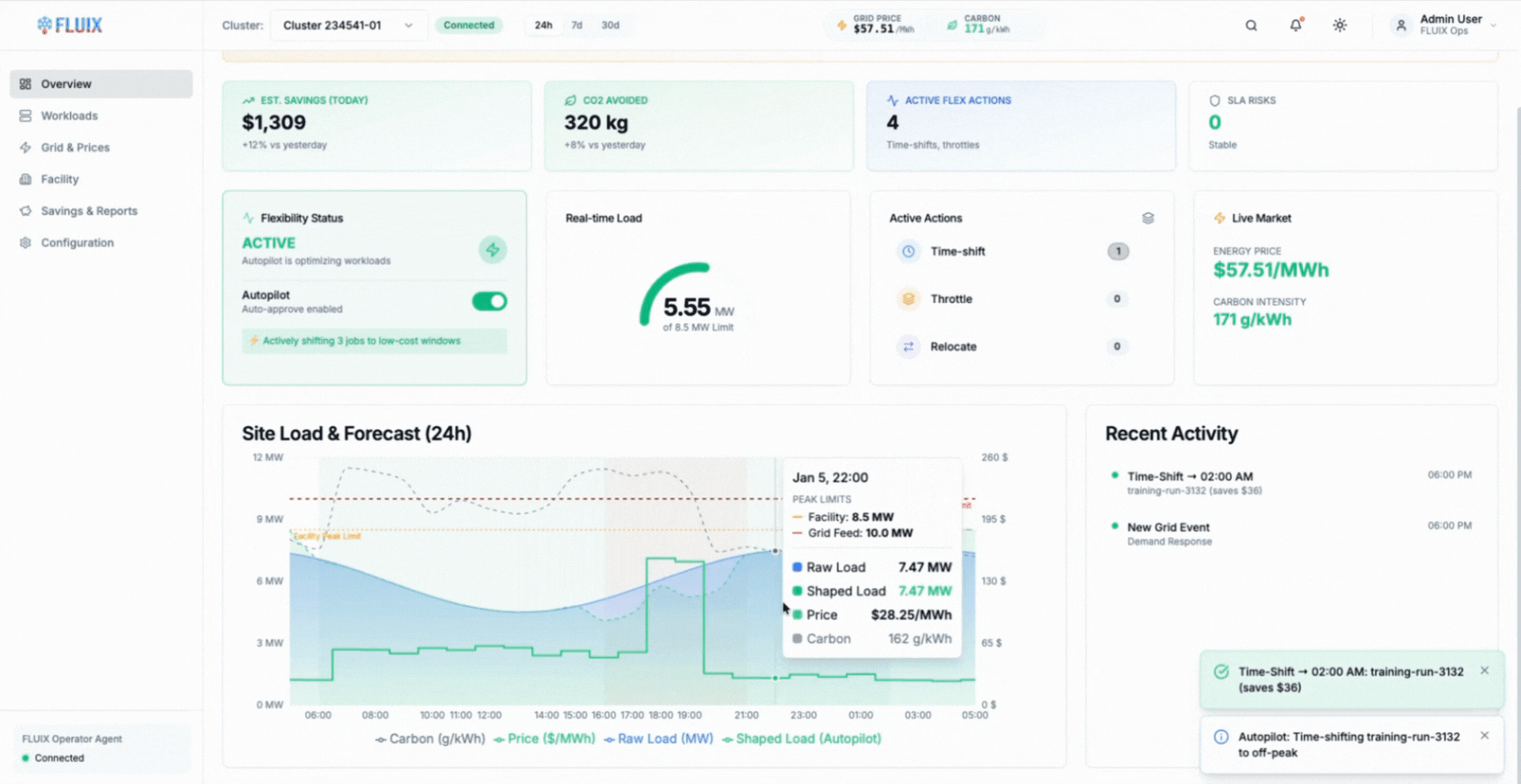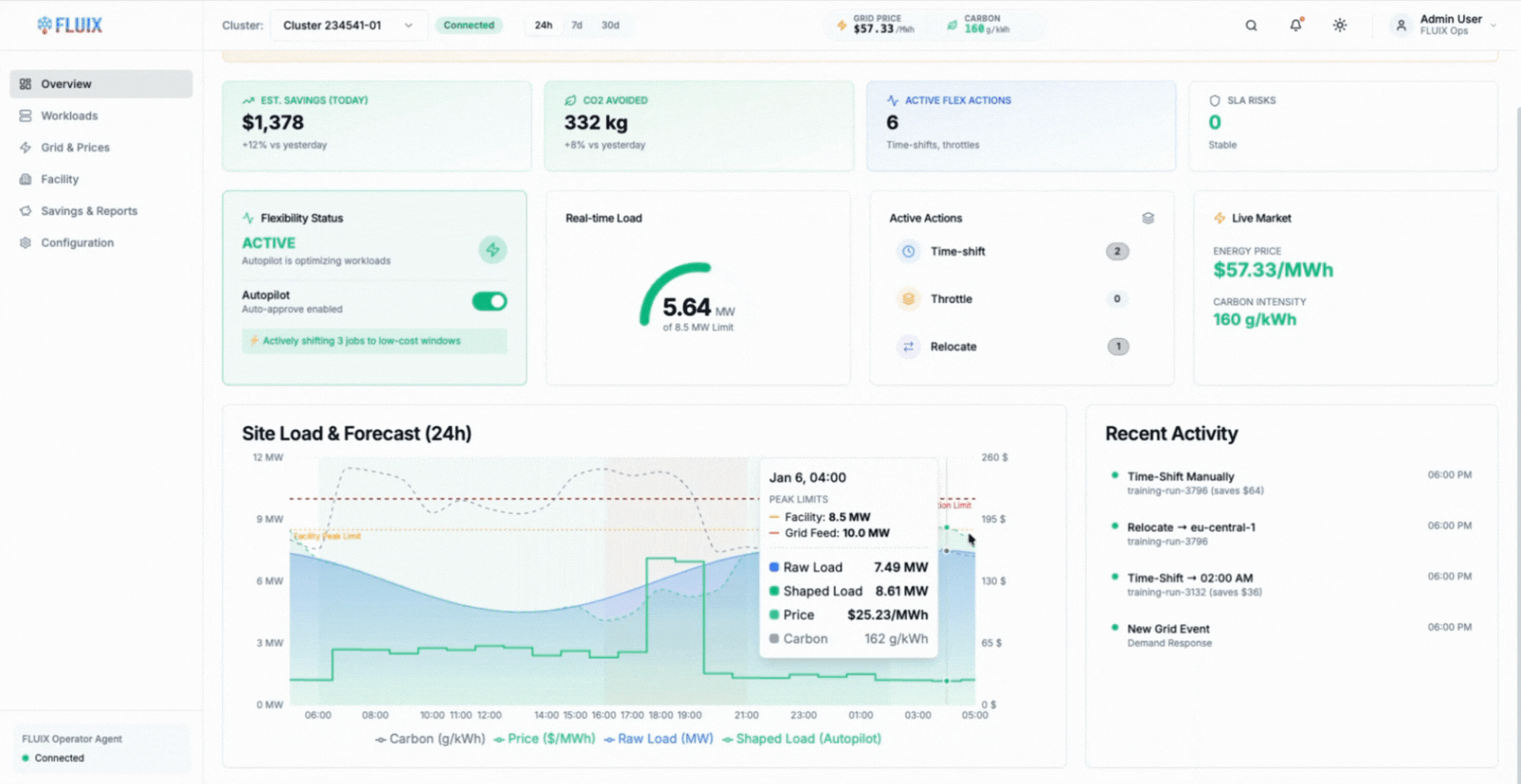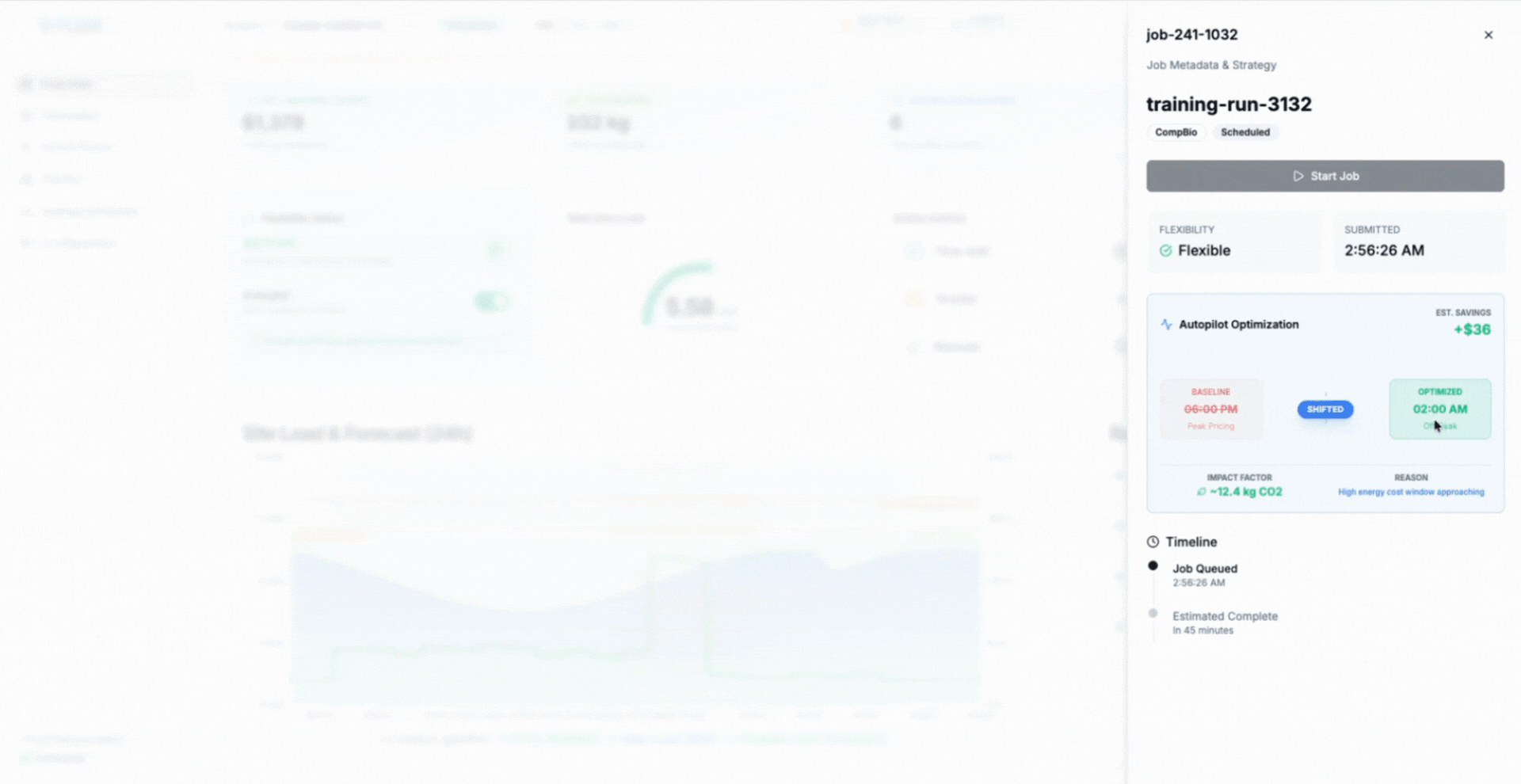
The animation shows AIMI delaying or slowing flexible training workloads during constrained periods, then resuming execution smoothly as power availability and cooling headroom recover.
Location Shifting: Moving Compute to Where Power Exists
Location shifting extends compute flexibility across geography. In multi-site deployments, flexible training workloads can be executed where power is cheaper, cleaner, or less constrained at a given moment, rather than remaining fixed to a single facility regardless of grid conditions.
Large cloud operators have used regional workload placement for years to balance capacity and reliability. Google has described how globally distributed infrastructure allows batch workloads to run where capacity is available, while latency-sensitive services remain pinned closer to users (Google, Borg: Large-scale cluster management). From the grid’s perspective, this turns compute into relocatable demand.
What limited broader adoption was operational complexity. Moving workloads across sites requires consistent environments, reliable data movement, and careful coordination. In colocation environments, especially, location shifting often remained manual or contractually constrained rather than driven by live conditions.
AIMI addresses this by treating location as another control dimension. By evaluating power availability, cooling capacity, and workload eligibility across sites, AIMI can direct flexible training jobs to locations with available headroom while preserving clear operational boundaries.
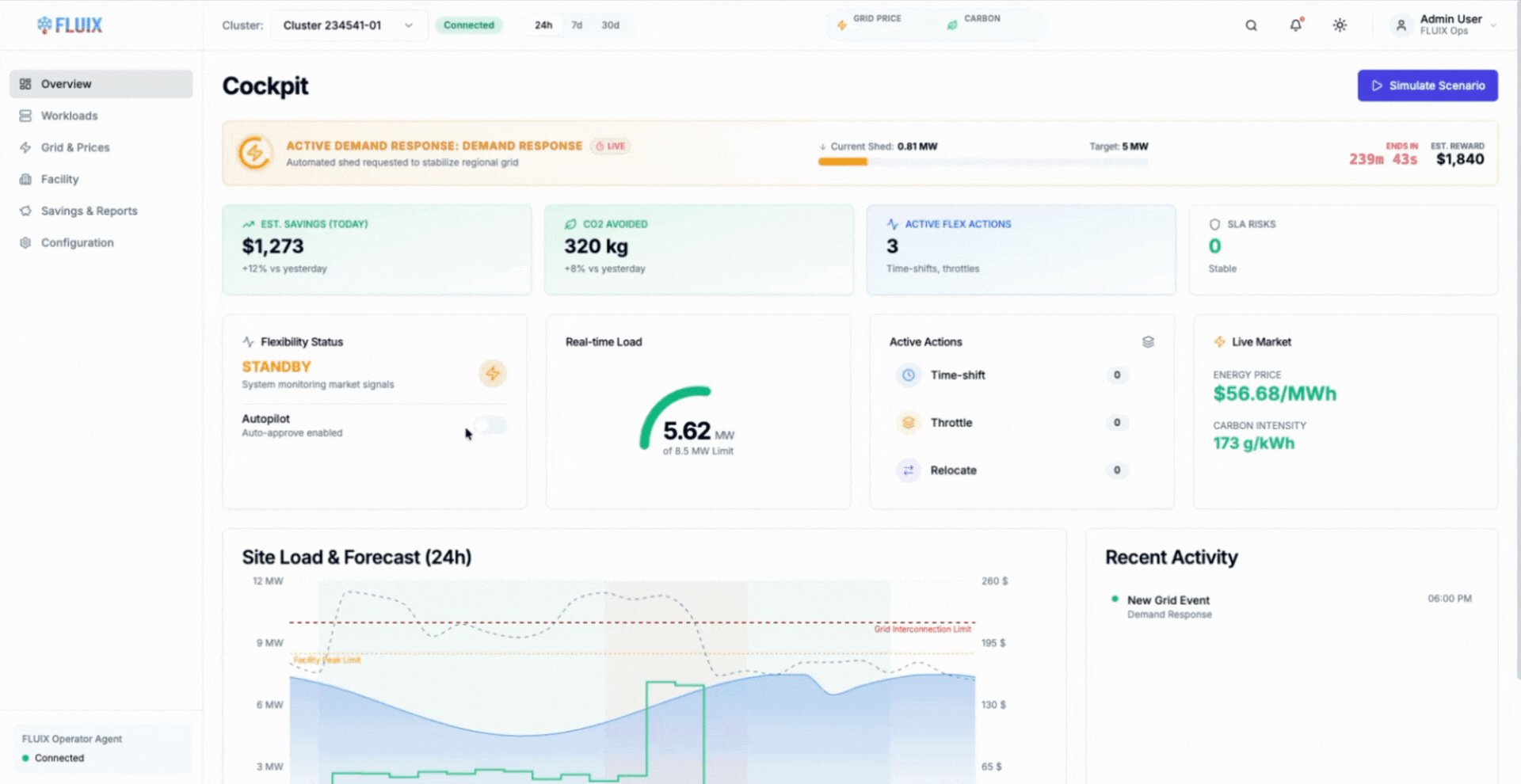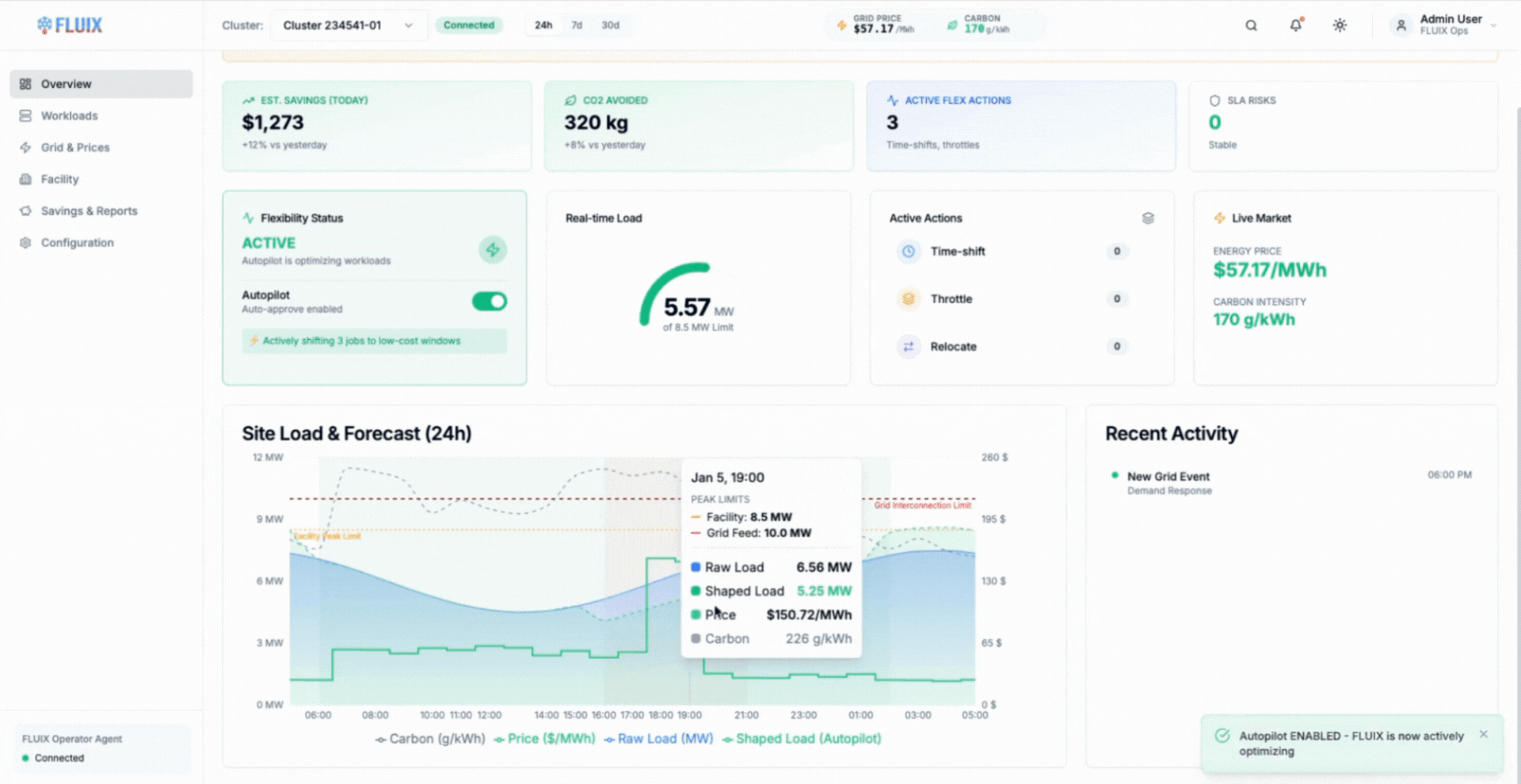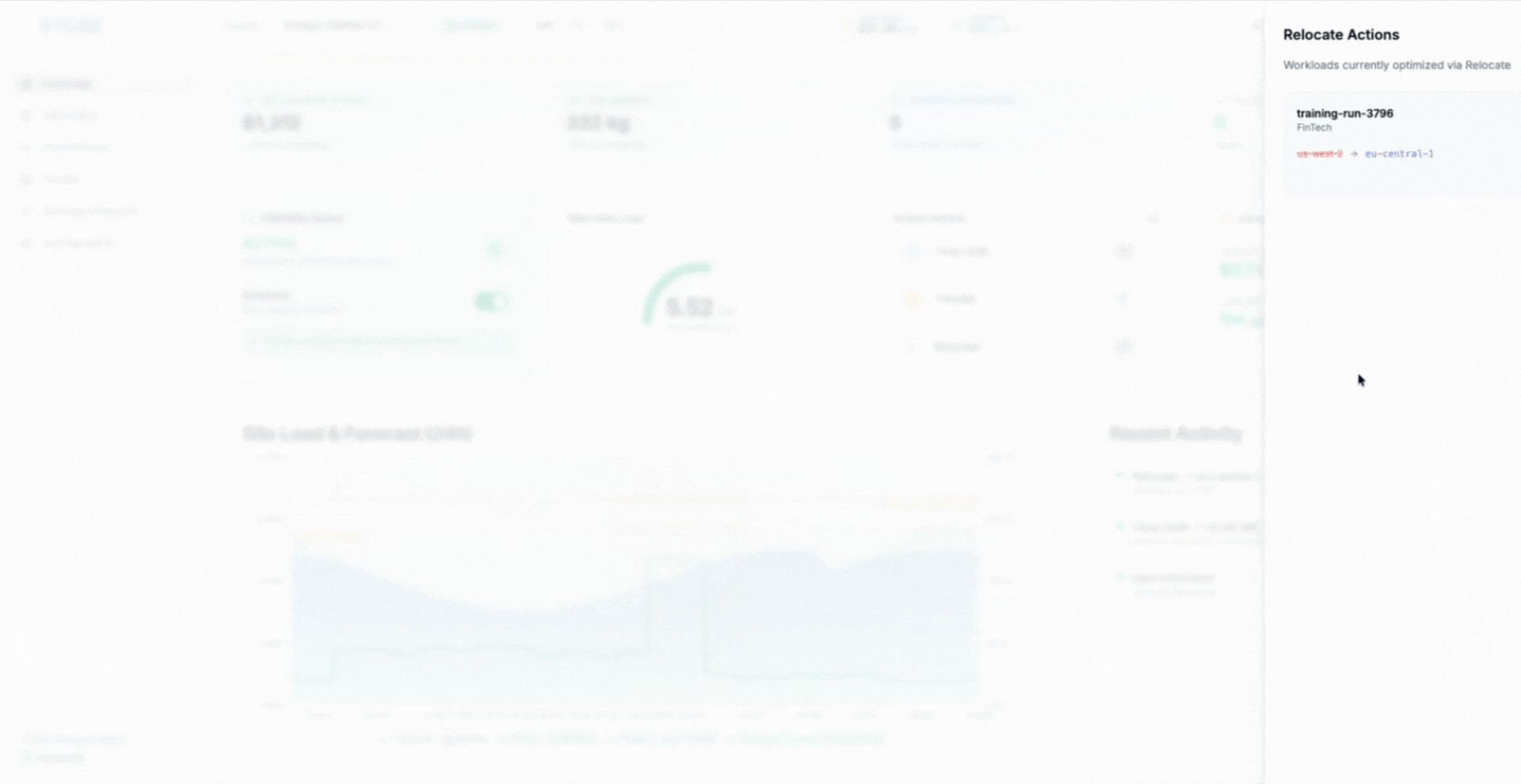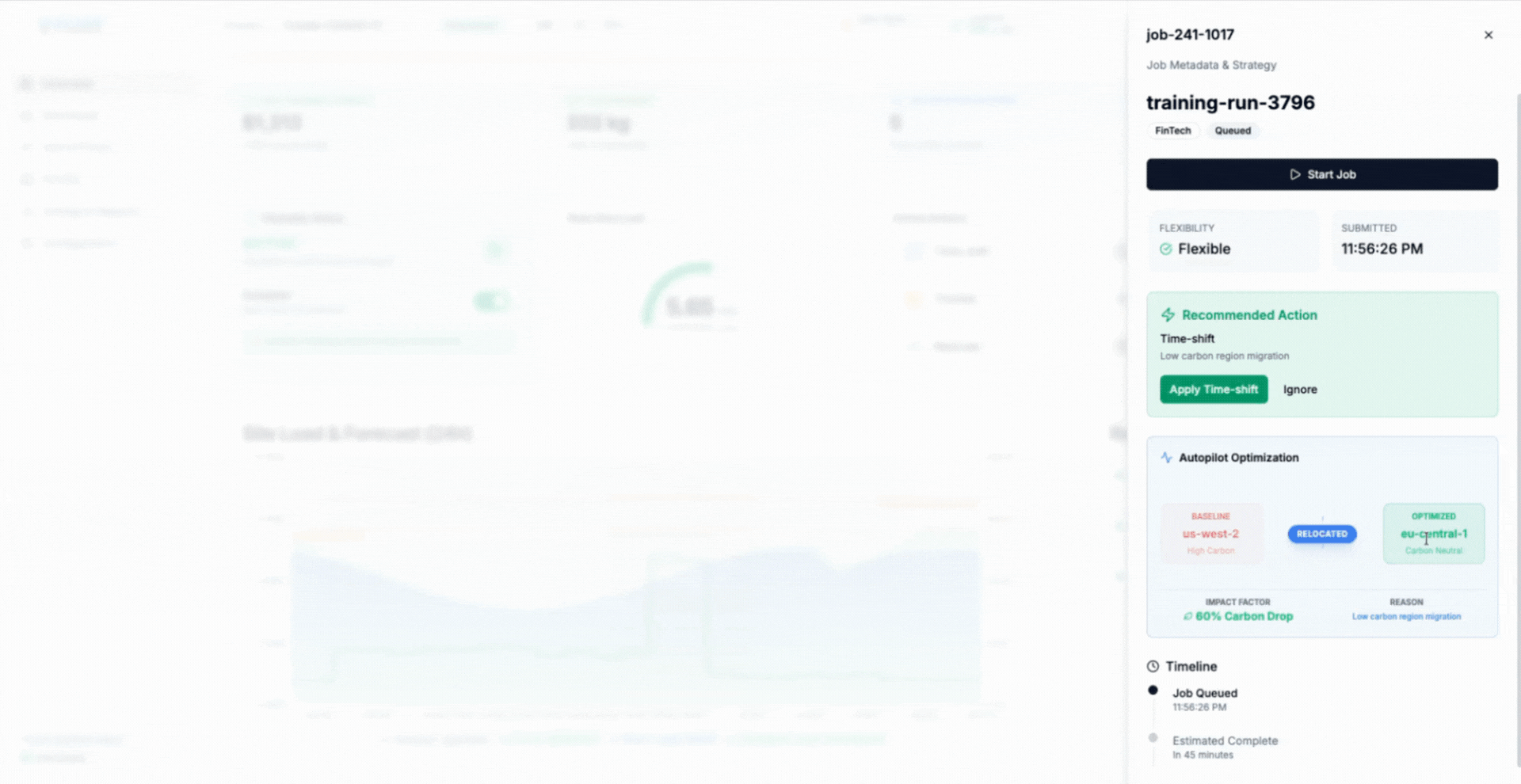
The animation illustrates how AIMI selects execution locations dynamically, shifting eligible workloads to facilities with available capacity and restoring them as conditions change.
Orchestration Is the Missing Layer
Introducing FLUIX A.I.M.I. Orchestrator - the Autonomous AI agent that optimizes compute workloads in mission critical data centers.
Across throttling, time shifting, and location shifting, the underlying challenge is the same. These mechanisms only work when compute, power, and cooling are treated as a single system, with decisions informed by real-time conditions rather than static rules.
Utilities have been explicit about why these mechanisms matter. The U.S. Department of Energy describes demand response and load flexibility as tools that allow electricity demand to be “adjusted in response to grid conditions,” enabling operators to maintain reliability without relying solely on new generation or transmission assets (U.S. Department of Energy, Demand Response and Load Flexibility; Federal Energy Regulatory Commission, Assessment of Demand Response & Advanced Metering)
That orchestration layer is what has been missing. AIMI is designed to be that layer.
For a practical walkthrough of how orchestration works in live environments, covering throttling, time shifting, and relocation, we break it down visually in our video explainer.
Watch: Compute Flexibility & Orchestration Explained
From Concept to Real Systems
Even at a small scale, one lesson becomes clear: treating compute, power, and cooling as a single system leads to better decisions than letting each operate independently.
This does not require specialized hardware. Most of the leverage comes from software, orchestration, and using the right signals at the right time. That philosophy shaped A.I.M.I. 1.0, our control system designed to coordinate cooling, power, and compute as one operational loop.
As our CTO has described it:
“We built A.I.M.I. to operate in real facilities, not idealized simulations. It learns within strict safety boundaries and makes decisions that respect physical infrastructure.”
The system architecture, experimental setup, and measured results from live environments are detailed in the A.I.M.I. 1.0 technical white paper
Read the A.I.M.I. 1.0 White Paper
Why This Matters Now
AI infrastructure will not scale by adding GPUs alone.
It will scale by making compute more flexible, more predictable, and more grid-aware, allowing training workloads to behave like controllable demand that can pause, resume, and relocate without breaking customer expectations. Data centers that adopt this approach will extract more value from existing capacity and integrate more cleanly with the power systems they depend on.
Compute flexibility is no longer theoretical, see how FLUIX is deploying Autonomous AI agents to orchestrate AI workloads in data centers - introducing A.I.M.I. Balancer - our compute orchestration platform.