
Most data centers cannot flex the workload. They can flex the facility.

Most data centers cannot flex the workload. They can flex the facility.
The real path to data center flexibility is not workload orchestration. It is facility-layer orchestration.
Everyone wants data centers to become more flexible. Meaning have the ability to move, shed, and reduce energy load during a grid congestion. For the last few decades, we’ve built data centers to be on 24 by 7 without risk of downtime. Recently, however, the idea of moving compute workloads by shifting when they start/stop, where they are run, and how intensely chips should run has taken the marketplace by storm. We cover how this works in our compute flexibility article. However, this framework does not work for most data centers.
Utilities want flexibility because grid capacity is getting harder to deliver. Operators want flexibility because power availability is becoming the new bottleneck for growth. Policymakers want flexibility because data center load is now large enough to affect regional planning, rates, and reliability.
But most of the conversation starts in the wrong place by assuming all data centers can move, pause, or throttle IT workloads when the grid is constrained. That may work for hyperscalers or AI data centers where the operator owns all equipment and services (vertically integrated). It does not work for most of the market.
Most commercial, colocation, enterprise, ISP, managed service provider, hospital, banking, and government data centers do not own the servers running inside their buildings. Their tenants do.
A colocation operator cannot pause a bank’s transaction system because the grid is peaking at 5 p.m. They cannot move a hospital workload across the country because a utility is short on capacity. They cannot throttle a government application because the local substation is constrained.
The operator does not control the tenant workload. They control the facility layer, where the flexibility is actually practical.
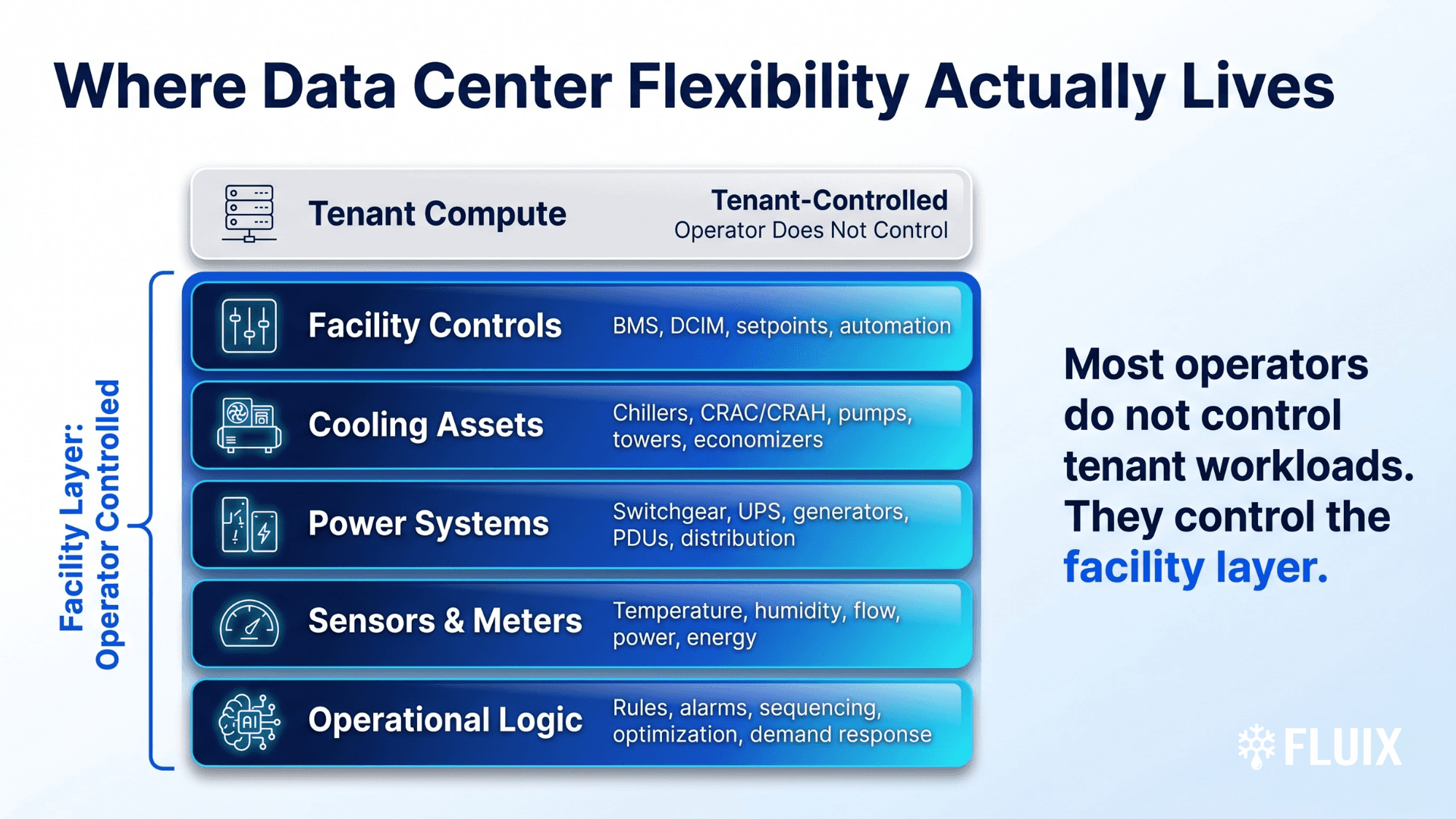
Most data center operators do not control tenant compute. They control the facility layer: cooling, power, controls, sensors, meters, and operating logic.
The grid is asking for flexibility because the load is real
U.S. data centers consumed about 176 TWh of electricity in 2023, equal to 4.4% of total U.S. electricity consumption, according to the 2024 Lawrence Berkeley National Laboratory report. By 2028, that number could rise to 325 to 580 TWh, or 6.7% to 12% of total U.S. electricity consumption.
That kind of growth changes the relationship between data centers and the grid.
A data center is no longer just a large customer at the edge of the power system. Increasingly, it is one of the defining loads shaping utility planning, transmission queues, local reliability, and economic development.
Uptime Institute’s 2024 survey makes the same point from the operator side: demand is growing not only in volume, but in compute intensity, challenging the power and cooling capabilities of much of the existing infrastructure.
Data Centers can become flexible, that is now known, however the methods of doing so is still being deliberated.
The question now becomes, where can most data centers actually flex (move, reduce, or curtail energy consumption) without risking uptime?
Workload flexibility is real, but limited
Compute flexibility is a powerful idea.
In the right environment, workloads can be time-shifted, throttled, relocated, or scheduled based on grid conditions, power price, carbon intensity, or cooling efficiency.
That is useful.
But it assumes the operator controls the workload.
Hyperscalers can build that stack because they often own the data center, the servers, the software layer, the workload scheduler, and the customer relationship.
Most data centers do not.
In colocation and commercial environments, the building owner or operator provides the critical infrastructure: power, cooling, network, physical security, and uptime. The tenant owns the server, the application, the SLA, and the business risk.
That means workload orchestration cannot be the default flexibility strategy for the majority of the market.
The other 99% need a different path.
They need facility-layer flexibility.
Facility-layer flexibility is the practical path
For most data centers, the controllable layer includes:
Cooling assets
Facility controls
Power systems
Sensors and meters
Onsite operational logic
Batteries, generators, and energy storage where available
Utility signals and demand response event windows
This is the layer the operator already manages.
It is also the layer that can be optimized without touching tenant servers.
That distinction matters. A mission-critical facility can participate in grid flexibility without becoming a hyperscaler, without rewriting customer contracts, and without asking every tenant for workload control.
The building itself can become more intelligent.
Cooling is the first lever
Cooling is often the best place to start.
Data centers are conservative by design. Operators overcool because downtime is unacceptable. If a thermal event happens, the consequences are immediate and expensive.
But that conservatism creates waste.
A data hall does not need the same cooling effort every minute of every day. IT load changes. Outdoor temperature changes. Humidity changes. Rack temperatures change. Utility constraints change. Equipment availability changes.
When cooling is treated as a static background process, operators waste energy and miss flexibility.
When cooling is orchestrated around the actual state of the facility, it becomes a grid asset.
FLUIX’s approach is simple: make data centers grid-flexible by flexing cooling load, not server load. In the presentation this article is based on, the core message was clear: FLUIX makes data centers into grid assets by flexing cooling load while not touching server load, using grid feeds from utility partners to optimize cooling without affecting data center performance.
That is the wedge that is safe and replicable across most sites. Also this does not require asking the operator to risk tenant workloads.
How thermal orchestration works
Thermal orchestration is the process of preparing, flexing, and recovering the cooling system around a grid event.
The basic playbook has three steps.
First, pre-cool before the event.
If the utility expects a constraint between 4 p.m. and 6 p.m., the data center can use the earlier window to build thermal headroom. Compressors, fans, pumps, economizers, or other cooling assets can run harder while the grid is less constrained.
Second, reduce mechanical effort during the peak event.
Once the event begins, the system can reduce compressor usage, adjust fan speeds, or change setpoints within safe operating limits. The facility uses the thermal headroom it already created.
Third, recover after the event - nominal conditions.

Once the grid constraint passes, the system returns to normal operation and restores thermal buffer. Its important to note, with the right guardrails and control redundancies, this thermal flexibility will not impact SLA or result in excursions. These redundancies need to be tested by human operators.
It is controlled operation inside a safe envelope. If temperatures rise too quickly, IT load spikes, humidity drifts, equipment faults, or the BMS calls for more cooling, the facility protection layer wins. Grid flexibility is always lower priority than uptime. That is the only way this works in mission-critical data centers.
This is not just theory
FLUIX has already proven this framework across multiple mission-critical data centers, with expansion underway.
The approach is intentionally conservative.
First, read the data.
Then make recommendations.
Then let operators validate.
Then, and only then, begin limited autonomous control inside guardrails.
In the field deployment model described in the presentation, FLUIX first reads data from energy meters and temperature sensors, then provides manual recommendations to the facility team, and by the third month earns trust to control one unit autonomously. The same presentation described this as a trust-building exercise that had been done across three sites, with expansion to six sites underway.
Given the risk of autonomy in mission critical systems such as data centers, there needs to be a framework to deploy safe and replicable automation that is true and tested. That is where FLUIX's Deployment Model comes into play. We've now deployed out Autonomous AI solution in multiple data centers across the US and LATAM. Demonstrating cooling flexibility across various geographies, data center types, and equipment. Here is the model that is working, time and time again.
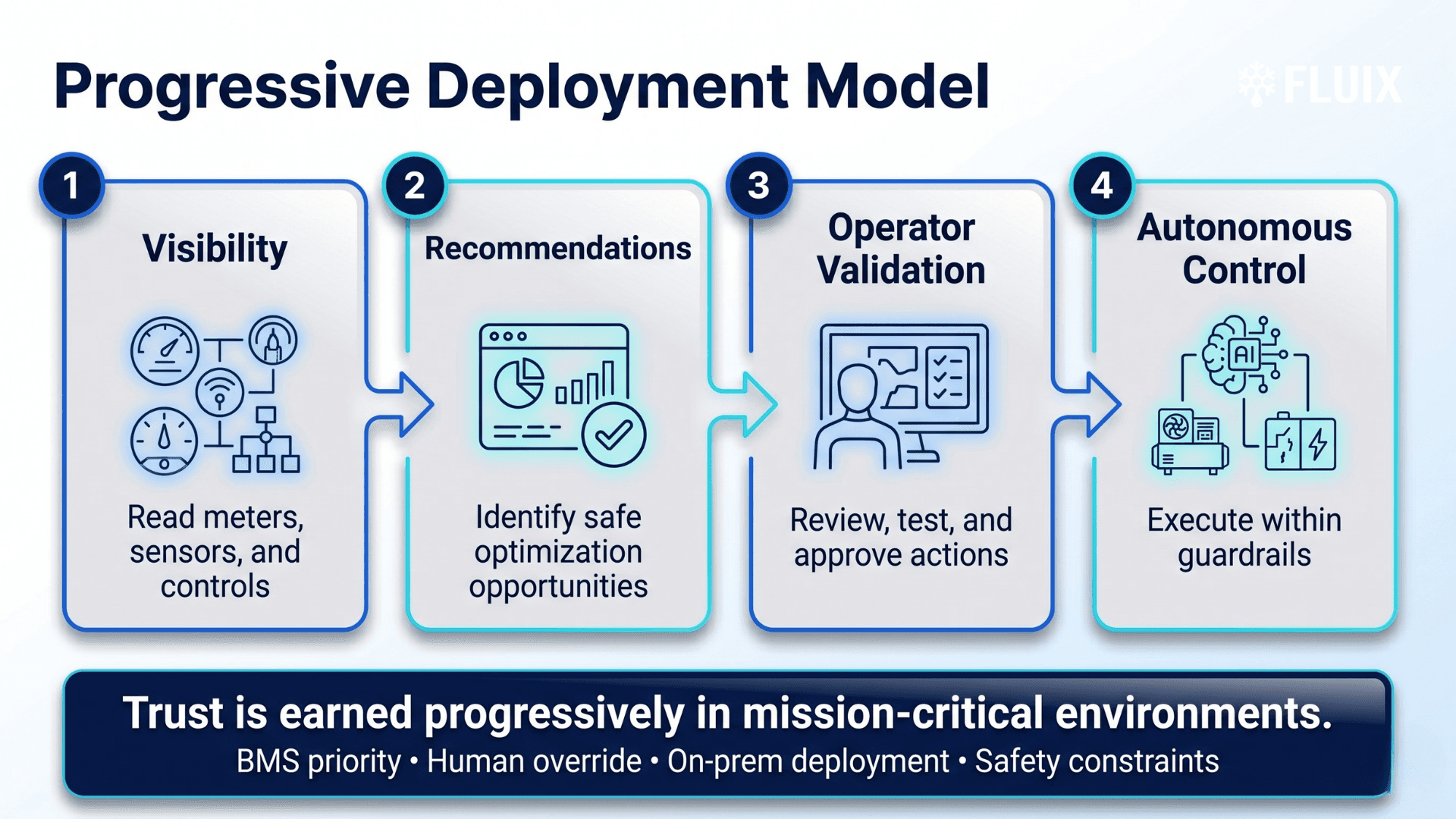
Mission-critical autonomy is earned progressively: visibility, recommendations, operator validation, then autonomous control within guardrails.
What operators need to start
A data center does not need to rebuild the entire facility to become flexible.
It needs a few foundational capabilities.
1. A grid or utility signal
The facility needs to know when the grid is constrained.
That signal can come from a utility, grid operator, and demand response provider. With our data center partners, we provide this through A.I.M.I.’s internal energy management system.
At the beginning, it does not need to be complicated. Even a basic dispatch window can be enough to test pre-cooling, peak response, and recovery.
2. Site and IT load visibility
Operators need to see total site load and IT load.
This matters because the cooling strategy must follow what the servers are doing. If IT load rises unexpectedly during a grid event, cooling flexibility should back off.
This is accomplished by having energy meters grabbing total power readings and isolated server power readings, usually at the UPS, PDUs, or tapboxes above the servers.
3. Thermal monitoring
Operators need real-time temperature, humidity, flow, and environmental data.
Thermal headroom is not a guess. It is measured.
If the system knows where the building has room and where it does not, it can make better decisions. This is accomplished through humidity and temperature sensors throughout the whitespace (in the data hall). The more the merrier, have them in the cold aisle, hot aisle, under the raised floor, on the ceiling tiles, or mid-way up a server rack.
4. Facility network access
Now all the aforementioned meters, sensors, cooling assets, and controls need to communicate. This is done by connecting all these systems to a facility network. Think of a large network of TCP/IP (ethernet for us civilians) that allows all the systems to communicate back to a central system. With our customers this is FLUIX A.I.M.I. the central intelligent data center automation system.
This is usually where the real work begins. Not in the dashboard. Not in the AI model. In the facility network, the BMS, the EMS, the naming conventions, the permissions, the protocols, and the operator workflow.
If the dispatch signal, energy meters, and temperature sensors can all speak over the facility network, a regular data center can become flexible by optimizing cooling during grid events.
That is the practical playbook.
Why utilities should care
Utilities are not just looking for energy efficiency.
They are looking for capacity.
They need large loads that can respond during constrained windows. They need ways to reduce peak stress without waiting years for new generation, transmission, and substation upgrades. They need load to become a participant in grid reliability.
DOE’s Data Center Load Flexibility Workshop made this point clearly. Data centers can potentially adapt their operations based on grid conditions and serve as grid assets through demand response, balancing intermittent energy sources, thermal storage, batteries, onsite generation, and advanced management software.
But the workshop also identified the hard part: traditional demand response programs and grid models do not fully account for the scale, growth, and dynamic load-shedding potential of data centers. Data centers prioritize uptime, and many operators are cautious about anything that could compromise reliability.
That is why facility-layer flexibility is so important.
It gives utilities a way to work with data centers without asking them to violate their core operating principle.
Protect uptime first while "flexing" what can safely be flexed.
The real incentive is speed to power
The demand response check is not the whole story.
For many data center operators, the bigger prize is speed to power and unlocking the most productive use of energy that they already have.
Utilities will prioritize methods that enable safe, measurable, repeatable flexibility for data centers. Prove that and these same utilities will help you connect faster, expand faster, or access better rate structures.
DOE’s workshop captured this exact point: normal financial incentives for demand response may not be valuable enough for owners, while speed-to-connection incentives could be much more powerful.
That should become a major part of how utilities think about data center load.
A flexible data center is not just a better customer during emergencies.
It is a lower-risk customer to connect.
If the site can prove that it can shed non-IT load safely during constrained windows, coordinate with utility dispatch, and maintain uptime while reducing mechanical demand, that should matter in interconnection and rate design.
Flexibility should be rewarded with a better path to capacity.
Why this needs software, not just equipment
Cooling equipment already exists.
Meters already exist.
BMS and EMS systems already exist.
The missing layer is orchestration.
Most sites were not designed to coordinate utility signals, IT load, thermal headroom, cooling assets, and power systems in real time. They were designed to keep the building safe and running.
That is necessary, but not sufficient for the next era.
The future data center needs an operating layer that can answer questions like:
What is the grid asking for?
What is the site capable of?
What is the IT load doing?
Where is thermal headroom available?
Which cooling assets can safely reduce effort?
When should the facility pre-cool?
When should the system recover?
When should automation stop and hand control back to the BMS?
This is where AI becomes useful as a control layer for physical infrastructure. Think of an autonomous vehicle: the intelligence knows exactly when to apply the gas, when to brake, how to turn the wheel, and when to signal. Similarly, an intelligence can determine when to increase fan speeds to eliminate hot spots, when to run compressors to manage rising outdoor humidity, or how to pre-cool a facility based on future grid events and pricing.
Safety is the product
The most important feature in this market is not autonomy.
It is safe autonomy.
That means on-premise deployment where needed. Operator visibility. Limited control scopes. Redundant fallback. BMS priority. Cybersecurity discipline. Clear override logic. No dependence on cloud connectivity for core safety decisions.
In the presentation, the deployment philosophy was explicit: FLUIX does not replace the BMS, it augments it. The software is deployed on-premise, inside the customer’s environment, and demand response is lower priority than the data center SLA. If the site needs more cooling, automation stops and the facility returns to the safe operating mode.
That is the correct posture.
A data center should never sacrifice reliability to chase a grid event.
The system should only flex when the building has room to flex.
The operator advantage
For operators, facility-layer flexibility creates three advantages.
First, lower waste and more power headroom for compute. That means power that can be turned into more revenue.
Cooling systems are often one of the largest controllable loads in a facility. Matching cooling effort to actual IT load, weather, and thermal state reduces unnecessary mechanical work.
Second, stronger utility relationships.
A data center that can respond to grid constraints is easier to partner with than one that behaves like a fixed block of demand.
Third, a better path to growth.
In a constrained power environment, operators that can prove flexibility may have an advantage in interconnection, rate design, expansion planning, and community acceptance.
The market is moving from “How much power do you need?” to “How intelligently can you use the power you get?”
That shift matters.
So the bottom line is…
Although workload shifting works, its often times not sensible for most sites given that operators don’t have access to tenant servers. However, most facilities can control and optimize their power and cooling systems controls. So stop asking every data center to flex compute.
The facility layer is where the practical flexibility lives. Cooling can flex. Power systems can coordinate.
Meters and sensors can inform those decisions. Controls can respond to volatile IT load to shed waste. Thermal headroom can be managed and coordinated with utility dispatch signals. And with FLUIX, that is already possible. The future of data center flexibility is not just workload orchestration. It is facility-layer orchestration across cooling, power, and compute. The hyperscalers will build custom compute stacks.
The rest of the market needs a way to make the data centers they already operate more intelligent, more efficient, and more grid-aware.
That is the real unlock on how most data centers can become flexible.

References
Lawrence Berkeley National Laboratory, 2024 United States Data Center Energy Usage Report, estimating U.S. data center electricity use at 176 TWh in 2023 and 325 to 580 TWh by 2028.
U.S. Department of Energy / Lawrence Berkeley National Laboratory, Data Center Load Flexibility Workshop Summary, covering grid-responsive operations, demand response barriers, speed-to-connection incentives, standardized utility-data center communication, and the need for AI-driven energy optimization tools.
Uptime Institute, Global Data Center Survey 2024, noting that rising digital demand and compute intensity are challenging the power and cooling capabilities of existing infrastructure.
